Amazonのアソシエイトとして、ラズパイダ(raspida.com)は適格販売により収入を得ています。詳しくは当サイトの プライバシーポリシーをご覧ください。
データを集計して分析するといった大袈裟なことではなく、これまでExcelのシートで関数やVAを使ってやっていたことをPythonでやるだけです。Excelを使わないで同じようなことを実現するのに適していると思います。
今回のようなプログラミングの場合、Windows・Macの環境でPythonが動く環境ならRaspberry Piは関係ありません。ラズパイの利点は、最初からPythonプログラムがそのまま動くことです。ローカルLAN内に入れれば閲覧する環境は問いません。
仮想環境もある時代ですから、Windows・Macでも同じことはできます。動きが分かる最低限のコードでご紹介します。
使用したExcelデータは、記事の最下部にリンクしておきます。試してみてください。
サンプルデータファイルを間違えたためアップロードし直しました。 テーブル表示部のコードを変更しました。そのため完成画像も変更しています。
Streamlitでダッシュボードを作成
今回は主にStreamlitを使います。そしてpandasが基本になります。StreamlitはPythonでWebアプリを簡単に扱えるフレームワークです。pandasはデータ解析使うライブラリです。
それに加え、xlsxファイルを扱うためopenpyxlも必要になり、グラフ表示させるためにplotlyも使います。
次の画像のようにExcelのデータから取り出したいデータを集計したりグラフ化したりWebブラウザで表示させます。元のデータファイルやプログラムコードを変更しても、ブラウザのリロードですぐに反映されて便利です。

ダッシュボード例
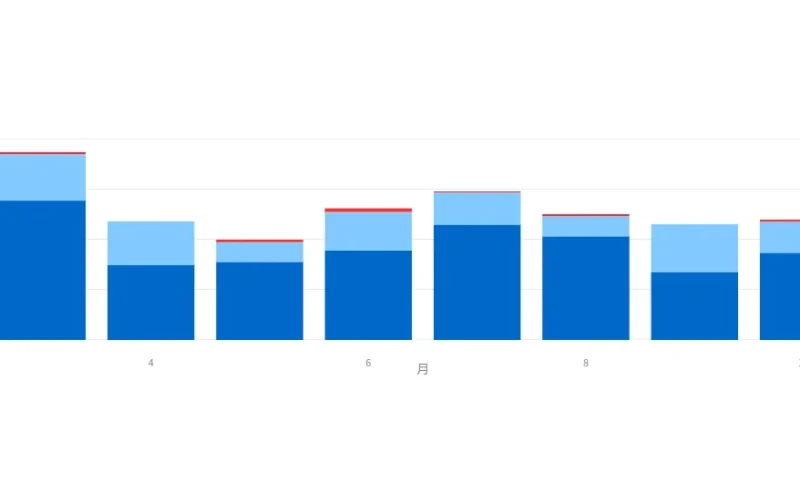
グラフ例
20年前、Excelでシート参照させて、セルに関数を忍ばせ、VBAで処理させていました。グラフはExcelの機能を使うことが多かったかな。
Excelファイルのデータを扱うのは同じでも、Streamlitはデフォルト動作でネットワーク越しに表示ができます。ラズパイ単体で展開したデータをLAN内のWebブラウザから表示できるのでお手軽です。
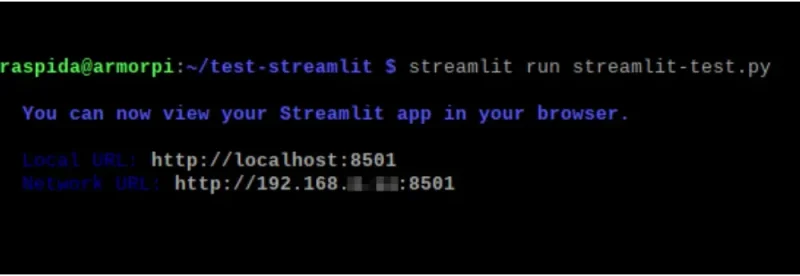
ラズパイ本体ならlocalhost:8501で表示されます。他のPCからならIPアドレスに8501ポート番号で表示できます。
StreamlitはPythonでここでご紹介する以上にたくさんの機能を使えます。今回は集計とグラフ表示だけにトライしました。
必要なライブラリ等のインストール
使用した環境は、Raspberry Pi OS Bullseye 64bitです。Raspberry Pi 4のmicroSDカードから起動させています。
必要なアプリやライブラリは、pipでインストールしてみました。
pip自体が入っていなければインストールしておきましょう。
sudo apt install python3-pip
pandasをpipでインストールすると、numpyがエラーになりインポートできない(らしい)文系のオッサンとしては、この辺りが昔からモヤモヤしている。あくまでもRaspberry Piに限ったこともあるため、OSのバージョンによってよく分からない。
今回、記事執筆時点ではpipでインストールして一応動作しました。OpenCVやTensorflowなどではまたチガウと思う。
ということを踏まえて、使いたいラブラリをインストールしていきます。
Streamlit、pandas、plotly、openpyxlが最低限必要でした。
sudo pip3 install streamlit
sudo pip3 install pandas
sudo pip3 install plotly
sudo pip3 install openpyxl
ちなみに、コマンドがpipかpip3かどうかもモヤモヤしますね。Raspberry Pi OS上ではいつもpip3で実行しています。
jinja2を3.03に
pipでインストールしたからか、pandasやplotlyとの関係か、記事執筆時点でjinjya2のバージョンが異なり動作しません。これを更新する必要がありました。3.0以上にしろと出ます。
jinja2のバージョンをプロジェクトサイトで調べると、2021-11-09版のバージョン3.0.3がありましたので、それを指定してインストールしました。
$ sudo pip3 install jinja2==3.0.3
作成の準備
実際のプログラミングにあたり、ネットにはたくさんの例が紹介されています。用意するExcelファイルによって異なります。ここでは集計とグラフ表示が目標です。
データとして、日付けがあり、商品名と単価、数量といったテストデータで試しました。自分が表示させたいExcelファイルに置き換えてコードを修正してください。
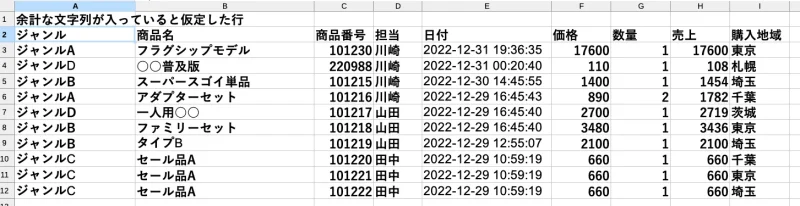
超テキトーですみませんが、次のようなExcel表データがあったとします。
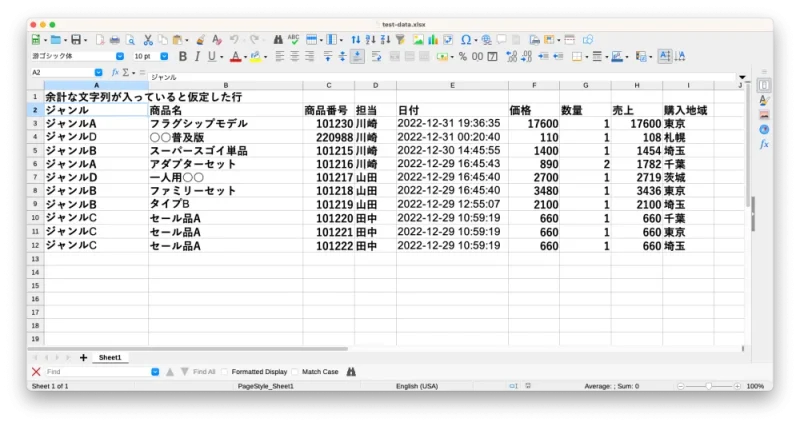
テストデータ例
これをRaspberry Pi の適当な場所にフォルダを作成してコピーしておきます。ここではフォルダ名をtest-streamlit、データファイル名はtest-data.xlsx、Pythonのpyファイル名はstreamlit-test.pyにしてあります。任意でどうぞ。
■Pi 5は8GBモデルがオススメ



Pythonコード例
ネットにはたくさん情報があります。最低限のテストができるように、各所の解説を読んで試してみました。
簡単なExcelデータを用意して、集計しただけに過ぎません。基本のコードは抑えられると思います。
今回のPythonコードを実行するには、Streamlit runコマンドで行います。
streamlit run ファイル名.py
コードは記事の最下部に記載しています。
途中でコードを実行して結果をみていくのも良いと思います。
importする
最初に各ライブラリをimportする記述です。
from datetime import date
import pandas as pd
import streamlit as st
import plotly.express as px
plotly.expressは簡単なコードでグラフを作成できます。
詳しくはgithubで確認してください。
GitHub
GitHub - plotly/plotly.py: The interactive graphing library for Python :sparkles: The interactive graphing library for Python :sparkles: - plotly/plotly.py
Excelファイルの読み込み
Excelのファフィルを読み込む記述です。
pd.read_excelで使えるパラメータは他にもあります。今回は最低限にファイル名、シート名、ヘッダー行、使用する列を指定します。
df = pd.read_excel("./test-data.xlsx", sheet_name="Sheet1", header=1, usecols="A:I")
headerは通常0からカウントしますから、1としたから2行目です。今回のテストデータの最初の行に要らない記述があったと仮定しているからです。1行目がヘッダーなら0になります。
データのセット
事前の処理としてデータタイプをセットし、月別も欲しいので日付けデータから月を取り出しておきます。
空白データを除外した方が良いということなので、df.dropna()も追加します。
df = df.dropna()
df[["価格","数量","売上"]] = df[["価格","数量","売上"]].astype(int)
df["日付"] = pd.to_datetime(df["日付"])
df["月"] = df["日付"].dt.month.astype(str)
今回は日付けが2022-12-31 19:36:35と年月日と時刻が入っていると仮定しています。データタイプを日付型にして、月だけ取り出すようにdt.monthで取り出しました。
Pythonってこの日付けの扱いってのが厄介でして、何かと色んなところで詰まりますね。
ページの設定
ページレイアウトの最初に、page_configでレイアウトをwideにしておきます。これで広く使えます。そして大タイトルとして文字列を指定しておきました。
st.set_page_config(
page_title="販売データのテスト",
layout="wide",
)
st.title("2022年度販売データ")
streamlitで使える表現はいくつもあります。ここではご紹介しませんが、ウィジェットとしてチェックボックス、スライダーやラジオボタン、入力欄などを表現できます。
集計欄3つ
続いて、3カラムに割った集計欄を作ります。
販売された数量の合計である販売個数と、売上金額の合計である総売上、そして販売された件数の販売件数です。
# 表示カラム数3
col1, col2, col3 = st.columns(3)
# 合計数量
count_items = df["数量"].sum()
col1.metric("販売数量", f"{count_items}個")
# 総売上
so_uriage = df["売上"].sum()
col2.metric("総売上", f"{so_uriage}円")
# 販売件数
count_suuryo = df["数量"].count()
col3.metric("販売件数", f"{count_suuryo}件")
列名をsum()するのが2つと、単に行数がいくつあるかのcount()が1つ。
それぞれcol1~3で横に3つ並べています。
サンプルデータの行数分で取得しているため、同商品名で表示すると件数が合わない状態になっています。
テーブルとグラフ
次にテーブルとグラフを表示させます。
2カラムで分け、左側に数字として集計している数量と売上をテーブルとして表示させ、2カラム目にグラフを月別・販売地域別に積み上げるグラフになっています。
# 表示カラム数2
col1, col2 = st.columns(2)
# テーブル表示
multi_df = df[["商品名","価格","数量","売上"]].groupby(["商品名","価格"]).agg('sum').applymap('{:,.0f}'.format).reset_index()
# multi_df = df.groupby(by="商品名").sum().sort_values(by="数量", ascending=False).reset_index()
col1.subheader('商品一覧')
col1.table(multi_df)
# 月毎の積み上げグラフ
m_group_df = df.groupby(["月", "購入地域"]).sum()
fig = px.bar(m_group_df.reset_index(), x="月", y="売上", color="購入地域", title="月別地域別グラフ")
col2.plotly_chart(fig, use_container_width=True)
テーブルは数量でソートしています。ascending=Falseなので降順で数字が大きい方から並んでいます。
テーブル表示部を変更しました。
単価である価格も合計されてしまいましたので、商品名と価格をグルーピングして、残りの数量と売上を.agg(‘sum’)で合計しています。ついでに、売上部分の数字を三桁カンマ表示にしています。
グラフの横軸(x)に月として、縦軸(y)に売上にしました。色分けしているのはcolorで指定された列データで、ここでは購入地域にしています。
テーブルのsubheaderはシングルコーテーションで括りました。
一応の完成
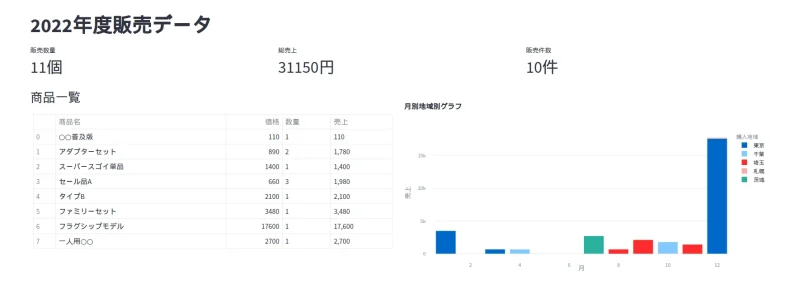
(クリックで拡大)
今回のテストデータで表示されたダッシュボードです。少し素っ気ないので、streamlitの機能を使ってもう少し見やすくしたいですね。
フレームワークというだけあって想像よりも簡単に表示できました。
xlsxファイルに追加と変更をしたり、コードを変更しても、Webブラウザのリロードで更新されます。(Autoでも出来る)データを直接変更して変化を見るのに楽ちんです。
コード自体を変更すれば、もっと絞り込んだデータにすることもできますし、グラフの種類を変更しても良いでしょう。詳しいパラメーターや書式は、ドキュメントを眺めてみてください。
エラーが出ても、(syntax error以外)どこを間違えているのかも分かりやすく感じました。
API referenceは英語でも分かりやすいと思います。例文や動画でとても実践的です。
同じことをExcelで表現するより使い勝手が良いですね。
複雑なことをしなくても、今回のような集計やグラフ化だけでも便利ですよ。
Webアプリになりますから、Excelではなくボタンが押されたら何かを処理させたり、別のプログラムを走らせたりといったことに使えます。
例えば、ラズパイに繋いだプリンターで印刷させるプログラムが別にあったとして、WebUIから入力したデータを基に決まった書式で印刷させる、といった入力用にも使えそうです。
何かの仕組みをWebアプリのUIで制御するのに、比較的に敷居が低い印象でした。
ラズパイはサーバにもなりますし、データベースも仕込めます。複雑にすると難しいので、先ずは既存のExcelデータの集計などで使ってみると、意外と楽しく感じるためオススメです。
Streamlit • A faster way to build and share data apps
PythonとStreamlitをRaspberry Pi OSで使ってみたお話でした。
サンプルデータ
記事で使用したサンプルデータとコードです。コードはコピペしてください。
2つのファイルは同フォルダ内に設置してください。
サンプルコード(動作はしますがテストコードです。上手く改変してください)
from datetime import date
import pandas as pd
import streamlit as st
import plotly.express as px
df = pd.read_excel("./test-data.xlsx", sheet_name="Sheet1", header=1, usecols="A:I")
df = df.dropna()
df[["価格","数量","売上"]] = df[["価格","数量","売上"]].astype(int)
df["日付"] = pd.to_datetime(df["日付"])
df["月"] = df["日付"].dt.month.astype(str)
st.set_page_config(
page_title="販売データのテスト",
layout="wide",
)
st.title("2022年度販売データ")
# 表示カラム数3
col1, col2, col3 = st.columns(3)
# 合計数量
count_items = df["数量"].sum()
col1.metric("販売数量", f"{count_items}個")
# 総売上
so_uriage = df["売上"].sum()
col2.metric("総売上", f"{so_uriage}円")
# 販売件数
count_suuryo = df["数量"].count()
col3.metric("販売件数", f"{count_suuryo}件")
# 表示カラム数2
col1, col2 = st.columns(2)
# テーブル表示
multi_df = df[["商品名","価格","数量","売上"]].groupby(["商品名","価格"]).agg('sum').applymap('{:,.0f}'.format).reset_index()
# multi_df = df.groupby(by="商品名").sum().sort_values(by="数量", ascending=False).reset_index()
col1.subheader('商品一覧')
col1.table(multi_df)
# 月毎の積み上げグラフ
m_group_df = df.groupby(["月", "購入地域"]).sum()
fig = px.bar(m_group_df.reset_index(), x="月", y="売上", color="購入地域", title="月別地域別グラフ")
col2.plotly_chart(fig, use_container_width=True)
テストデータの日付けは複数の月に変更してあります。
これまでのPythonの記事
記事中にも書きましたが、Raspberry Pi OSなら、最初からPython言語が動作する環境が整っています。microSDカードにOSを書き込むだけです。
はじめてプログラム言語に取り組むなら、比較的にPythonは容易だと言われています。
本業ではないのなら、コードのコピペから始めてみてはいかがでしょうか。
ラズパイはちょどいい

Pythonならすぐに始められます